Hace unas semanas, en un evento justo antes del inicio de la Gamescom en Colonia, Alemania, el CEO de NVIDIA, Jensen Huang, dio a conocer oficialmente la línea inicial de tarjetas gráficas de la serie GeForce RTX 2000 de la compañía, basada en su nueva microarquitectura de GPU Turing. Jensen analizó varias de las nuevas características y capacidades de las tarjetas, incluido el trazado de rayos acelerado por hardware en tiempo real, una nueva tecnología de suavizado asistido por aprendizaje profundo denominada DLSS, y cubrió algunas velocidades y alimentaciones específicas con respecto a las próximas tarjetas GeForce RTX.
Muchos otros detalles técnicos más profundos con respecto a la microarquitectura de la GPU de Turing se mantuvieron más cerca del chaleco y solo se revelaron a un grupo más pequeño de asistentes al evento. Sin embargo, hoy podemos divulgar algunos de esos detalles técnicos y características, y los presentaremos en las páginas siguientes. Sin embargo, antes de profundizar, también tuvimos la suerte de tener al propio Tom “TAP” Petersen de NVIDIA en un podcast reciente para hablar sobre Turing y la serie GeForce RTX en su conjunto. Durante nuestra charla, se revelaron algunos datos interesantes. Si lo desea, le recomendamos encarecidamente que consulte esto también …
La línea inicial de tarjetas gráficas de la serie GeForce RTX 2000 está compuesta por GeForce RTX 2070, RTX 2080 y RTX 2080 Ti. También hay Ediciones de Fundador con mayor frecuencia de reloj de cada carta. Todas las tarjetas se basan en la microarquitectura Turing de NVIDIA y ofrecen características similares, pero también funcionan con diferentes variantes de GPU Turing. La GeForce RTX 2080 Ti de gama alta se basa en la GPU TU102, la RTX 2080 se basa en la TU104 y la RTX 2070 en la TU106.
El diagrama de bloques anterior es una representación de la configuración completa de TU102. El TU102 se compone de aproximadamente 18.6B transistores, y cuando está completamente habilitado presenta 72 multiprocesadores de transmisión (SM), 4,608 núcleos CUDA, 576 núcleos Tensor, 72 núcleos RT (Ray Tracing), 36 unidades geométricas (TPC), 288 unidades de textura, 96 ROP, una interfaz de memoria de 384 bits (12 canales) y canales NVLink duales. Sin embargo, tenga en cuenta que la GeForce RTX 2080 Ti insignia no cuenta con la habilitación completa de TU102.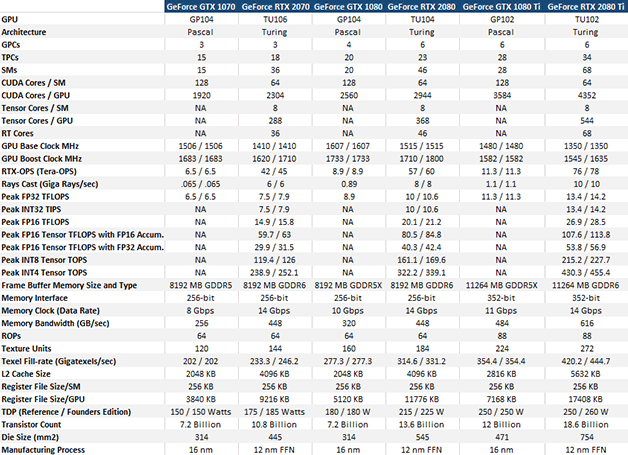
Comparación de las especificaciones de la tarjeta NVIDIA GeForce RTX
La nueva tarjeta gráfica Quadro RTX 6000 pro de NVIDIA funciona con un TU102 totalmente habilitado, pero la GeForce RTX 2080 Ti tiene dos TPC, cuatro SM, 256 núcleos CUDA, cuatro núcleos RT, ocho ROP, 16 unidades de textura y un canal de memoria deshabilitado ( específicamente, 4352 núcleos CUDA, 552 núcleos Tensor y 68 núcleos RT en el RTX 2080 Ti). Las configuraciones de reloj, memoria y recuento de núcleos exactos para todas las tarjetas de la serie GeForce RTX 2000 basadas en Turing, Quadro RTX 6000 y sus contrapartes basadas en Pascal se representan en la tabla anterior. Definitivamente haga clic en esa imagen y dedique un tiempo a revisar las especificaciones, porque hay una tonelada de datos para digerir, incluidos algunos términos nuevos que quizás no haya escuchado antes.
Como notará, la GeForce RTX 2080 y RTX 2070 tienen el mismo conjunto de características que su hermano mayor, pero sus recuentos de núcleos y configuraciones de memoria se reducen aún más (y sus diagramas de bloques parecen un poco más pequeños). Los recuentos de transistores para TU102 y TU104 también se reducen proporcionalmente. Sin embargo, lo que vale la pena señalar es cuánto más grandes son en realidad las GPU de Turing en comparación con Pascal. A pesar de estar fabricados en un proceso Fin-Fet de 12 nm más denso y avanzado, todas las GPU basadas en Turing no solo tienen recuentos de transistores mucho más altos que sus predecesores, sino que también son chips mucho más grandes.
Los tamaños de troquel significativamente más grandes en las GPU GeForce RTX basadas en Turing, a pesar de estar fabricadas en un proceso más avanzado, se deben principalmente a las tecnologías adicionales que NVIDIA incorporó a los chips. Con la serie GeForce RTX, NVIDIA quería que las tarjetas funcionaran bien con los métodos tradicionales de sombreado y rasterización utilizados en todos los juegos de hoy (y de ayer), pero también quería sentar las bases para la IA, el aprendizaje profundo y el trazado de rayos. juegos y aplicaciones habilitados que espera sean el futuro, de ahí la adición de núcleos RT y Tensor a la mezcla. Todos esos núcleos adicionales equivalen a una cantidad adicional de transistores y un tamaño de matriz más grande, simple y llanamente.
Con núcleos CUDA adicionales, que también son más eficientes y tienen algunas capacidades nuevas, un ancho de banda de memoria significativamente mayor y un mayor rendimiento de texturizado, las tarjetas GeForce RTX basadas en Turing también deberían ofrecer más rendimiento con los títulos existentes, al mismo tiempo que admiten las nuevas tecnologías habilitadas por el Núcleos RT y Tensor, y el marco de software relacionado de NVIDIA.
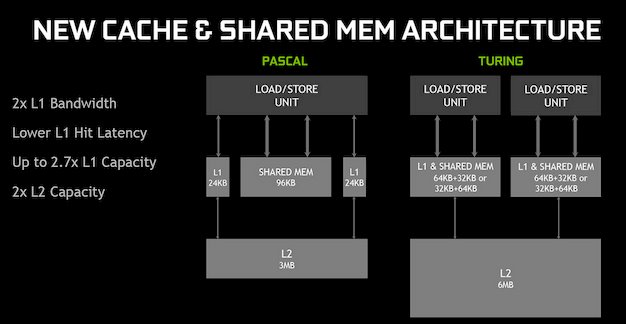
Sin embargo, además de los nuevos procesadores de Turing, NVIDIA ha diseñado optimizaciones significativas para mejorar la utilización, el rendimiento y la eficiencia de los sombreadores y otras unidades de la GPU. Por ejemplo, la canalización matemática en Turing se ha renovado y optimizado y ahora puede emitir instrucciones de punto flotante y enteros al mismo tiempo. Con algunas cargas de trabajo, NVIDIA afirma que este ajuste por sí solo puede aumentar el rendimiento en aproximadamente un 36%.
Las GPU basadas en Turing de NVIDIA también tienen el doble de caché L2 que sus predecesoras y la caché L1 ha sido equipada con un bus más ancho que finalmente duplica el ancho de banda. También hay más memoria caché L1 total y memoria compartida, y la configuración se ha cambiado para que sea más simétrica. Los cambios en Turing pueden resultar en un sombreado hasta un 50% más rápido dentro de los núcleos CUDA, pero las GPU también tienen esos núcleos Tensor y Ray Tracing a su disposición.
Los desarrolladores tendrán que aprovechar explícitamente esos nuevos núcleos, por supuesto, pero agregarán algunas capacidades significativas en caso de que se utilicen. Los núcleos Tensor, que son ideales para cargas de trabajo de aprendizaje profundo, como el reconocimiento de imágenes y la inferencia, ofrecen hasta 110TFLOPs de rendimiento de cómputo con cargas de trabajo FP16, o 228 o 445 TOPS con cargas de trabajo INT8 o INT4, respectivamente, en el TU102 al menos – aquellos los números son obviamente más bajos en los TU104 y TU106 más pequeños. Los núcleos RT pueden ofrecer hasta “10 Giga Rays / seg” en el TU102, que es una métrica de rendimiento algo nebulosa por sí misma en este momento, pero considere esto: una GeForce GTX 1080 Ti ofrece hasta 11.3 TFLOPS de cómputo rendimiento, puede manejar alrededor de 1.1 Giga Rays / seg, o aproximadamente 10 TFLOPS por Gigaray. En resumen, la GeForce GTX 2080 Ti es aproximadamente 10 veces más rápida que una GeForce GTX 1080 Ti con la misma carga de trabajo de trazado de rayos.

También debemos mencionar que todos los motores de procesamiento dentro de Turing (los sombreadores, los núcleos RT, los núcleos Tensor) se pueden utilizar simultáneamente, pero la unidad de envío solo puede alimentar dos unidades simultáneamente. Sin embargo, dado que los núcleos tensoriales suelen ser para cargas de trabajo especializadas y se aprovechan en una etapa diferente del proceso de renderizado, no poder alimentar los tres simultáneamente no debería ser un problema para los desarrolladores.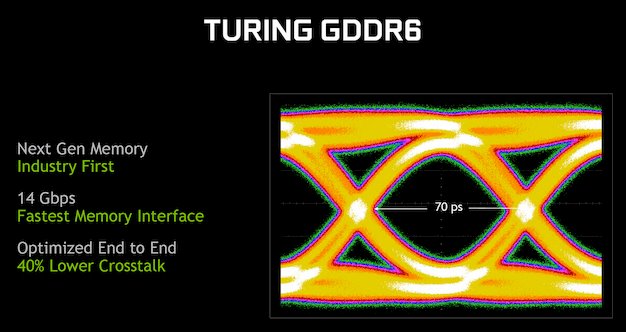
Para asegurarse de que Turing tenga acceso rápido a una gran cantidad de datos, NVIDIA también ha incorporado un controlador de memoria GDDR6 de última generación en las GPU. El ancho de banda por pin con la memoria GDDR6 empleada en las tarjetas iniciales de la serie GeForce RTX 2000 alcanza un máximo de 14 Gb / s (7 GHz) efectivos. Para lograr esa velocidad de datos, NVIDIA tuvo que optimizar la arquitectura del circuito de E / S y prestar especial atención al canal entre la GPU y las matrices de memoria individuales para garantizar la señalización más limpia posible (con lo que GDDR6 también ayuda inherentemente). Además del GDDR6 de alta velocidad, Turing también presenta una tecnología de compresión de memoria más avanzada que Pascal. Por lo tanto, las tarjetas de la serie GeForce RTX no solo ofrecen más ancho de banda, sino que el ancho de banda se utiliza de manera más eficiente.
El ancho del bus de memoria de 256 bits de las GeForce RTX 2070 y 2080, junto con esa velocidad de datos efectiva de 14 Gb / s, da como resultado 448 GB / s de ancho de banda máximo disponible, que es mucho más alto que los 256 GB / s (+ 75%) y 320GB / s (+ 39%) de la generación anterior de NVIDIA GeForce GTX 1070 y GTX 1080. El bus más ancho de 352 bits en la insignia GeForce GTX 2080 Ti da como resultado un ancho de banda de memoria máximo de 616GB / s, que es un aumento del 27% con respecto al 484GB / s de la GeForce GTX 1080 Ti.
Echemos un vistazo más de cerca a las nuevas tarjetas GeForce RTX Founder’s Edition de NVIDIA, a continuación …
