Overfitting is een veelvoorkomend probleem bij machine learning, waarbij een model goed presteert op trainingsgegevens, maar niet goed generaliseert naar ongeziene gegevens (testgegevens). Als een model lijdt aan overfitting, zeggen we ook dat het model een hoge variantie heeft, wat kan worden veroorzaakt door te veel parameters, wat leidt tot een model dat te complex is gezien de onderliggende gegevens. Evenzo kan ons model ook lijden onaangepastheid (high bias), wat betekent dat ons model niet complex genoeg is om het patroon in de trainingsdata goed vast te leggen, en daarom ook slecht presteert op de ongeziene data.

Overfitting en underfitting kunnen het best worden geïllustreerd door een lineaire beslissingsgrens te vergelijken met meer complexe niet-lineaire beslissingsgrenzen, zoals weergegeven in de volgende afbeelding:

De afweging van bias-variantie
Onderzoekers gebruiken vaak de termen “bias” en “variantie” of “bias-variantie tradeoff” om de prestaties van een model te beschrijven; dat wil zeggen, u kunt lezingen, boeken of artikelen tegenkomen waarin mensen zeggen dat een model “hoge variantie” OF “hoge vooringenomenheid” heeft. Dus wat betekent dat? In het algemeen zouden we kunnen zeggen dat “hoge variantie” evenredig is met overfitting en “hoge bias” evenredig is met onderfitting.
In de context van machine learning-modellen meet variantie de consistentie (of variabiliteit) van de voorspelling van het model voor het classificeren van een bepaald voorbeeld als we het model meerdere keren opnieuw trainen, bijvoorbeeld op verschillende subsets van de trainingsgegevensset. We kunnen stellen dat het model gevoelig is voor de willekeur van de trainingsgegevens. De bias meet daarentegen hoe ver de voorspellingen verwijderd zijn van de algehele correcte waarden als we het model meerdere keren opnieuw opbouwen op verschillende trainingsdatasets; Bias is de maat voor systematische fout die niet te wijten is aan willekeur.
Een manier om een goede afweging tussen bias en variantie te vinden, is door de complexiteit van het model aan te passen met regularisatie. Regularisatie is een zeer nuttige methode om collineariteit (hoge correlatie tussen kenmerken) aan te pakken, ruis uit de gegevens te filteren en uiteindelijk overfitting te voorkomen.
Overfitting aanpakken door regularisatie
Het concept achter de regularisatie is om aanvullende informatie (bias) te introduceren om de extreme waarden van de parameters te bestraffen (weging). De meest voorkomende vorm van regularisatie heet L2 regularisatie (soms ook L2-contractie of gewichtsverlies genoemd), wat als volgt kan worden geschreven:
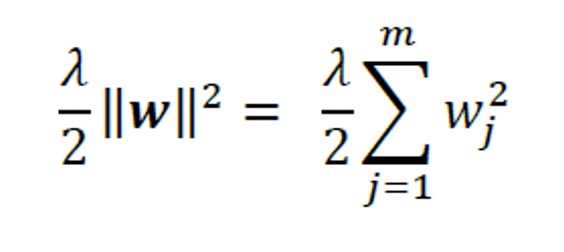
Hier is 𝜆 de zogenaamde regularisatieparameter.
Opmerking: regularisatie is een andere reden waarom het schalen van functies, zoals standaardisatie, belangrijk is. Om regularisatie goed te laten werken, moeten we ervoor zorgen dat al onze functies zich op vergelijkbare schaal bevinden.
De kostenfunctie voor logistische regressie kan worden geregulariseerd door een eenvoudige regularisatieterm toe te voegen, die de gewichten tijdens modeltraining zal verminderen:

Via de regularisatieparameter, 𝜆, kunnen we controleren hoe goed we ons aanpassen aan de training
gegevens, waardoor de gewichten klein blijven. Door de waarde van 𝜆 te verhogen, vergroten we de sterkte van regularisatie.
De parameter, C, die is geïmplementeerd voor de LogisticRegression-klasse in scikitlearn
komt van een conventie in ondersteuningsvectormachines. De term C is direct gerelateerd aan de regularisatieparameter, 𝜆, die het omgekeerde is. Bijgevolg betekent het verlagen van de waarde van de inverse regularisatieparameter, C, dat we de regularisatiesterkte verhogen, wat we kunnen visualiseren door het L2-regularisatiepad uit te zetten voor de twee wegingscoëfficiënten:
>>> gewichten, parameters = [], []
>>> voor c in np.arange (-5, 5):
… Lr = Logistieke regressie (C = 10. **c, random_state = 1,
… solver = ‘lbfgs’, multi_class = ‘ovr’)
… Lr.fit(X_train_std, y_train)
… peso.append (lr.coef_[1])
…params.toevoegen(10.**c)
>>> gewichten = np.array (gewichten)
>>> plt.plot (parameters, gewichten[:, 0],
… Tag = ‘bloemblad lengte’)
>>> plt.plot (parameters, gewichten[:, 1]lijnstijl = ‘-‘,
… Tag = ‘bladbreedte’)
>>> plt.ylabel (‘gewichtscoëfficiënt’)
>>> plt.xlabel(‘C’)
>>> plt.legend (loc = ‘linksboven’)
>>> plt.xscale(‘record’)
>>> plt.show()
Met de bovenstaande code passen we 10 logistische regressiemodellen met verschillende waarden voor de inverse regularisatieparameter, C. Voor illustratieve doeleinden verzamelen we alleen de gewichtscoëfficiënten voor klasse 1 (hier de tweede klasse in de dataset: Iris -versicolor ) versus alle classificaties; onthoud dat we de OvR-techniek gebruiken voor classificatie met meerdere klassen.
Zoals we in de resulterende grafiek kunnen zien, krimpen de gewichtscoëfficiënten als we de parameter C verlagen, dat wil zeggen, als we de regularisatiesterkte verhogen:

In dit artikel heb je geleerd over een machine learning-algoritme dat wordt gebruikt om overfitting-problemen aan te pakken. is een uitgebreide gids voor machine learning en deep learning met Python, scikit-learn en TensorFlow 2 met dekking van GAN’s en versterkend leren.
Over de Auteurs
Sebastian Raschka is assistent-professor statistiek aan de Universiteit van Wisconsin-Madison en richt zich op machine learning en deep learning-onderzoek. Sommige van zijn recente onderzoeksmethoden zijn toegepast om problemen op het gebied van biometrie op te lossen om privacy te verlenen aan gezichtsbeelden. Andere onderzoeksgebieden zijn de ontwikkeling van methoden met betrekking tot modelevaluatie in machine learning, deep learning voor ordinale doelen en toepassingen van machine learning op computationele biologie. Vahid Mirjalili behaalde zijn Ph.D. in de werktuigbouwkunde werken aan nieuwe methoden voor grootschalige computationele simulaties van moleculaire structuren. Momenteel richt hij zijn onderzoeksinspanningen op machine learning-toepassingen op verschillende computer vision-projecten in het Department of Computer Science and Engineering aan de Michigan State University. Hij trad onlangs in dienst bij 3M Company als onderzoekswetenschapper, waar hij zijn expertise gebruikt en geavanceerde deep learning- en machine learning-technieken toepast om echte problemen op te lossen in verschillende levensverbeterende toepassingen.


