Los teléfonos inteligentes han sido durante mucho tiempo más que simples teléfonos. Todos los días usamos nuestro dispositivo para chatear con amigos, ver videos en YouTube, comunicarnos en Telegram y, al mismo tiempo, hoy el teléfono para muchos puede convertirse en un reemplazo de una computadora completa. No estoy bromeando, estoy listo para mostrar con mi ejemplo cómo las redes neuronales de Google pueden escribir un artículo para mí. Hasta hace poco, era escéptico acerca de la entrada de voz que está integrada en el teclado gBoard, pero decidí intentarlo y me sorprendió mucho lo bien que el teclado puede reconocer mi voz. En este artículo, veremos cómo la empresa logró crear un reconocimiento de voz de tan alta calidad y cómo esta función puede ayudarnos en nuestro trabajo.

Todo este tiempo he estado escribiendo artículos usando mi computadora portátil o PC. Siempre me ha resultado más fácil expresar mis pensamientos con la voz que con los dedos. Esto hace que el proceso de expresar pensamientos sea más natural, más suave (buen flujo) y más rápido. Escribir con el teclado a menudo me llevó a situaciones en las que perdí el hilo de mis pensamientos. Ya estoy listo para publicar el segundo artículo dictado por mi teléfono, bueno, y no necesito tener una impresión rápida a ciegas de diez dedos al mismo tiempo (quiero señalar que soy bueno escribiendo). La capacidad de escribir material con voz me hace sentir feliz por lo mucho que ha avanzado la tecnología. Si antes podía escribir material en una o dos horas de mi tiempo, ahora logro reducir estos indicadores en 2 veces simplemente porque la expresión de pensamientos con la voz es más rápida que con el teclado.
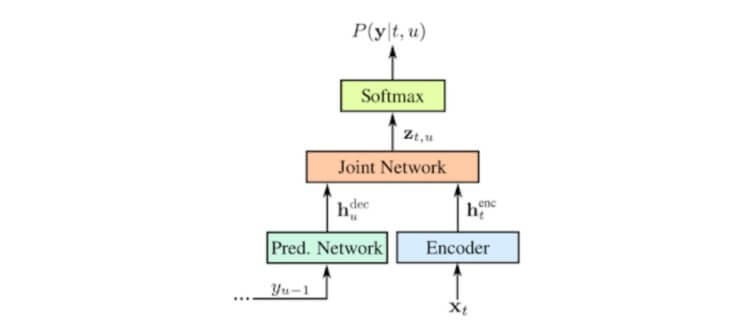
Estudié cómo funciona la entrada de voz de gBoard y, para ser honesto, me sorprendió. Anteriormente, la empresa utilizaba métodos de reconocimiento de voz bastante antiguos, que se basaban en el modelo de mezcla gaussiana. Este modelo se ha utilizado durante 30 años. Sin embargo, todo eso cambió en 2012 cuando las redes neuronales comenzaron a popularizarse. Por supuesto, existían antes, pero fue en 2012 cuando comenzó una nueva etapa de desarrollo. Se empezaron a utilizar redes neuronales profundas, recurrentes y otras. Y es el último tipo de redes neuronales el que subyace a la tecnología de reconocimiento de voz. Google utiliza actualmente la arquitectura de transductores de redes neuronales recurrentes (RNN-T) para el reconocimiento de voz. Y ahora los propietarios de teléfonos inteligentes Pixel pueden usar la entrada de voz gBoard sin Internet. Esto se logró a través de varias etapas de optimización, una de las cuales fue la compresión final, por lo que el tamaño del modelo original se redujo de 2 gigabytes a 80 megabytes. Propongo discutir esto en Telegram.
Los sistemas tradicionales de reconocimiento de voz tienen varios componentes: un modelo que divide el audio en fragmentos de 10 milisegundos, llamados fonemas, un modelo de pronunciación que une los fonemas para formar palabras y un modelo de lenguaje que ofrece al usuario frases listas para usar. En los primeros sistemas, estos componentes funcionaban de forma independiente entre sí. Alrededor de 2014, los investigadores comenzaron a centrarse en entrenar una red neuronal general para alimentar un archivo de audio como entrada y recibir una oración terminada en la salida. Este método de secuencia a secuencia hizo posible que el reconocimiento fuera más preciso, pero funcionó solo después de que se ingresó la oración completa. Mientras tanto, existía la tecnología CTC, que permitió reducir el retraso en el reconocimiento, en ese momento era un paso serio hacia la creación de redes neuronales recurrentes con convertidores RNN-T. A partir de este momento, fue posible reconocer con precisión en el momento de la entrada de voz directa.
¿Qué conclusiones se pueden sacar de todo esto? Por supuesto, ya puede utilizar la entrada de voz para un reconocimiento preciso del texto en ruso, y antes no funcionaba tan bien. Hasta ahora, lamentablemente, la red neuronal no es capaz de entender dónde colocar los símbolos de puntuación, sin embargo, el reconocimiento en sí es bastante preciso, lo que inspira la esperanza de que en el futuro se nos ofrecerán aún más oportunidades. No excluyo que en los próximos dos años Google adaptará su nueva red neuronal para trabajar con el idioma ruso en modo offline. Mientras tanto, estaremos contentos con lo que tenemos.
Comparta su opinión en los comentarios utilizando la entrada de idioma.
Basado en materiales de Google
