El sobreajuste es un problema común en el aprendizaje automático, donde un modelo se desempeña bien en los datos de entrenamiento, pero no se generaliza bien a los datos no vistos (datos de prueba). Si un modelo sufre de sobreajuste, también decimos que el modelo tiene una alta varianza, que puede ser causada por tener demasiados parámetros, lo que lleva a un modelo que es demasiado complejo dados los datos subyacentes. Del mismo modo, nuestro modelo también puede sufrir desajuste (sesgo alto), lo que significa que nuestro modelo no es lo suficientemente complejo para capturar bien el patrón en los datos de entrenamiento y, por lo tanto, también tiene un bajo rendimiento en los datos no vistos.

Los problemas de sobreajuste y desajuste se pueden ilustrar mejor comparando un límite de decisión lineal con límites de decisión no lineales más complejos, como se muestra en la siguiente figura:

La compensación sesgo-varianza
A menudo, los investigadores utilizan los términos “sesgo” y “varianza” o “compensación de sesgo-varianza” para describir el rendimiento de un modelo; es decir, puede tropezar con charlas, libros o artículos en los que la gente dice que un modelo tiene una “alta variación “O” alto sesgo “. ¿Entonces que significa eso? En general, podríamos decir que la “alta varianza” es proporcional al sobreajuste y el “alto sesgo” es proporcional al desajuste.
En el contexto de los modelos de aprendizaje automático, la varianza mide la consistencia (o variabilidad) de la predicción del modelo para clasificar un ejemplo en particular si reentrenamos el modelo varias veces, por ejemplo, en diferentes subconjuntos del conjunto de datos de entrenamiento. Podemos decir que el modelo es sensible a la aleatoriedad de los datos de entrenamiento. Por el contrario, el sesgo mide qué tan lejos están las predicciones de los valores correctos en general si reconstruimos el modelo varias veces en diferentes conjuntos de datos de entrenamiento; El sesgo es la medida del error sistemático que no se debe a la aleatoriedad.
Una forma de encontrar una buena compensación entre sesgo y varianza es ajustar la complejidad del modelo mediante la regularización. La regularización es un método muy útil para manejar la colinealidad (alta correlación entre características), filtrar el ruido de los datos y, finalmente, evitar el sobreajuste.
Abordar el sobreajuste mediante la regularización
El concepto detrás de la regularización es introducir información adicional (sesgo) para penalizar los valores extremos de los parámetros (ponderación). La forma más común de regularización es la denominada Regularización L2 (a veces también llamado contracción L2 o disminución de peso), que se puede escribir de la siguiente manera:
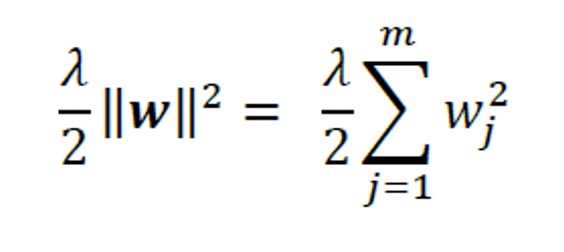
Aquí, 𝜆 es el llamado parámetro de regularización.
Nota: la regularización es otra razón por la que la escala de características, como la estandarización, es importante. Para que la regularización funcione correctamente, debemos asegurarnos de que todas nuestras funciones estén en escalas comparables.
La función de costo para la regresión logística se puede regularizar agregando un término de regularización simple, que reducirá los pesos durante el entrenamiento del modelo:

A través del parámetro de regularización, 𝜆, podemos controlar qué tan bien nos adaptamos al entrenamiento
datos, manteniendo los pesos pequeños. Al aumentar el valor de 𝜆, aumentamos la fuerza de regularización.
El parámetro, C, que se implementa para la clase LogisticRegression en scikitlearn
proviene de una convención en máquinas de vectores de soporte. El término C está directamente relacionado con el parámetro de regularización, 𝜆, que es su inverso. En consecuencia, disminuir el valor del parámetro de regularización inverso, C, significa que estamos aumentando la fuerza de regularización, que podemos visualizar trazando la ruta de regularización L2 para los dos coeficientes de ponderación:
>>> pesos, params = [], []
>>> para c en np.arange (-5, 5):
… Lr = Regresión logística (C = 10. ** c, random_state = 1,
… solver = ‘lbfgs’, multi_class = ‘ovr’)
… Lr.fit (X_train_std, y_train)
… pesos.append (lr.coef_[1])
… Params.append (10. ** c)
>>> pesos = np.array (pesos)
>>> plt.plot (parámetros, pesos[:, 0],
… Etiqueta = ‘longitud del pétalo’)
>>> plt.plot (parámetros, pesos[:, 1], linestyle = ‘-‘,
… Etiqueta = ‘ancho del pétalo’)
>>> plt.ylabel (‘coeficiente de peso’)
>>> plt.xlabel (‘C’)
>>> plt.legend (loc = ‘superior izquierda’)
>>> plt.xscale (‘registro’)
>>> plt.show ()
Al ejecutar el código anterior, ajustamos 10 modelos de regresión logística con diferentes valores para el parámetro de regularización inversa, C.Para fines ilustrativos, solo recopilamos los coeficientes de peso de la clase 1 (aquí, la segunda clase en el conjunto de datos: Iris -versicolor) versus todos los clasificadores; recuerde que estamos usando la técnica OvR para la clasificación multiclase.
Como podemos ver en la gráfica resultante, los coeficientes de peso se encogen si disminuimos el parámetro C, es decir, si aumentamos la fuerza de regularización:

En este artículo, aprendió sobre un algoritmo de aprendizaje automático que se utiliza para abordar los problemas de sobreajuste. es una guía completa para el aprendizaje automático y el aprendizaje profundo con Python, scikit-learn y TensorFlow 2 con una cobertura sobre las GAN y el aprendizaje por refuerzo.
Sobre los autores
Sebastián Raschka es profesor asistente de estadística en la Universidad de Wisconsin-Madison y se centra en el aprendizaje automático y la investigación de aprendizaje profundo. Algunos de sus métodos de investigación recientes se han aplicado a la resolución de problemas en el campo de la biometría para impartir privacidad a las imágenes faciales. Otras áreas de enfoque de investigación incluyen el desarrollo de métodos relacionados con la evaluación de modelos en el aprendizaje automático, el aprendizaje profundo para objetivos ordinales y las aplicaciones del aprendizaje automático a la biología computacional. Vahid Mirjalili obtuvo su Ph.D. en ingeniería mecánica trabajando en métodos novedosos para simulaciones computacionales a gran escala de estructuras moleculares. Actualmente, centra sus esfuerzos de investigación en aplicaciones de aprendizaje automático en varios proyectos de visión por computadora en el Departamento de Ciencias e Ingeniería de la Computación de la Universidad Estatal de Michigan. Recientemente se unió a 3M Company como científico investigador, donde utiliza su experiencia y aplica técnicas de aprendizaje automático y aprendizaje profundo de última generación para resolver problemas del mundo real en diversas aplicaciones para mejorar la vida.
